今天是2025年10月18日。当我们被“通用人工智能”的宏大叙事冲昏头脑时,AI世界却以一种分裂而深刻的姿态,同时演绎着“效率狂飙”与“智能谎言”的悖论。李飞飞团队用一块H100瓦解了世界模型的算力神话,火山引擎用强化学习革新了视频理解的效率,AI Agent正在以200%的速度改写软件测试。然而,宾大的一项研究却冷酷地揭示:对AI“粗鲁”一点,它反而更准。更令人警醒的是,AI教父本吉奥团队的新定义,如同手术刀般精准地剖开了当前大模型的“能力扭曲”,直指其在记忆、推理等核心智能维度上,得分竟是刺眼的0分。这不禁让我们自问:我们正在拥抱的,究竟是真正的智能革命,还是一个被效率假象掩盖的“伪通用AI”?而作为人类,又将如何与这些高效却又“愚蠢”的数字幽灵共舞?
今日速览:
- 李飞飞RTFM:单卡H100驱动世界模型,颠覆算力神话。 世界模型的算力高墙被一举击穿,标志着AI从“蛮力计算”向“智慧效率”的划时代转折,开启了AI Agent和沉浸式虚拟世界的民主化进程。
- 本吉奥团队重定义AGI,戳穿大模型“0分”短板。 AI教父本吉奥领衔发布AGI新定义,以人类心智为尺,犀利揭示当前大模型在长期记忆、即时推理等关键认知能力上存在0分短板,并提出“能力扭曲”概念,撕裂了“通用智能”的虚假繁荣。
- 宾大研究反直觉:对ChatGPT-4o“粗鲁”指令可提升4%准确率。 这项研究挑战人机交互基石,揭示在算法世界中,效率可能压倒礼节,引发对Prompt工程、商业效率及AI伦理的深层反思。
- AI Agent重塑软件测试:从“编写”到“描述”的效率跃迁。 TRAE智能体结合大模型与Playwright,将自动化测试效率提升200%,准确率高达92%,宣告自主系统软件质量保障新纪元的到来,测试工程师角色将被重新定义。
世界模型算力革命:李飞飞RTFM如何重塑AI Agents与虚拟未来
【AI内参·锐评】 李飞飞的RTFM一举击穿世界模型“算力壕沟”,宣告AI从“蛮力驱动”向“智慧计算”的划时代转折。但这并非终点,而是对下一代通用智能核心构件的深刻反思。
【事实速览】 李飞飞的创业公司World Labs近日发布RTFM(Real-Time Frame Model)世界模型,通过架构创新将运行算力需求大幅降至单个NVIDIA H100 GPU。这一突破性技术实现了实时渲染并与用户交互一个持久一致的3D世界,瓦解了世界模型部署长期面临的高门槛。RTFM不仅加速了AI Agent和沉浸式虚拟世界的普及,更预示着AI自主学习和构建现实的新范式,对产业格局和人类与数字世界的交互方式产生深远影响。
【背景与动机】 算力成本一直是AI领域,特别是大型模型和复杂系统发展的最大瓶颈。OpenAI的Sora(虽非完整世界模型但具备建模能力)峰值运行时被估算需要高达72万块H100 GPU的算力支持,几乎将其置于少数超大型科技公司才能企及的“象牙塔”之中。RTFM直接瞄准这一痛点,通过高效的架构设计(如自回归扩散Transformer、空间记忆机制)将这一门槛大幅降低至“单卡”,无异于在世界模型的赛道上,为无数创新者打开了全新的大门,旨在“民主化”AI,激发中小企业创新。
【投资者必读】 资本将更青睐那些能够通过算法和架构创新实现算力效率跃升的项目。未来,衡量AI公司竞争力的维度将不再仅仅是其能够调用多少块顶级GPU,更在于其能够以最少的算力撬动最大的智能输出。这预示着一场从“算力军备竞赛”到“算力效率竞赛”的范式转变。对于投资者而言,这意味着新的投资蓝海,应重点关注那些能在边缘计算、嵌入式设备等场景下,实现高效AI部署的创新企业。
【我们在想】 当AI能以极低成本构建无限逼真的虚拟世界,人类如何界定真实与虚假?这会是通往AGI实现具身智能的关键跳板,还是一个可能让人类沉迷其中、无法自拔的“甜蜜的囚笼”?
【信息来源】
- 来源: infoq.cn, 新浪财经, Analytics India Magazine
- 链接: https://www.worldlabs.ai/blog/rtfm, https://finance.sina.com.cn/tech/roll/2025-10-17/doc-infuepas8836821.shtml, https://analyticsindiamag.com/ai-news-updates/openais-sora-takes-about-12-minutes-to-generate-1-minute-video-on-nvidia-h100/
TempSamp-R1:强化学习重塑视频理解范式,开启智能内容生产新纪元
【AI内参·锐评】 火山引擎与南开大学的TempSamp-R1,不只是视频时序理解的SOTA刷新,更是强化学习在内容生产领域的一次“降维打击”,宣告AI视频理解从“看清”迈向“看懂”,进而“创造”的商业爆发期。
【事实速览】 火山引擎多媒体实验室与南开大学联合研发的TempSamp-R1强化学习新框架,在NeurIPS 2025上发布,通过混合策略采样、非线性优势塑造和混合CoT训练三大创新,显著提升了视频大模型的时序理解能力。该框架在CharadesSTA、ActivityNet Captions等数据集上刷新SOTA纪录,已集成至火山引擎「V-Orbit」平台,构建起“高光检测→智能剪辑”的完整技术闭环,重塑智能视频内容生产和商业应用工作流。
【弦外之音】 如果说李飞飞的RTFM让AI能低成本构建虚拟世界,那么TempSamp-R1则让AI能精准理解这个世界(或真实世界视频)中的动态事件和关键时序。二者合力,构成AI Agent构建、理解并作用于虚拟/现实世界的关键拼图。这不仅是技术突破,更是字节跳动作为内容巨头,在AI基础设施层面的战略卡位,通过赋能内容理解与生产效率,进一步巩固其在数字内容生态中的主导地位。
【开发者必读】 强化学习不再是纸上谈兵的学术概念,其在处理复杂时序、决策任务上的优势被TempSamp-R1的成功进一步验证。开发者应深刻理解并实践如何将RL与多模态模型深度结合,解决实际应用中的动态、不确定性问题。尤其是在AIGC与内容科技领域,从智能推荐到个性化创作,RL的潜力正被加速释放。
【我们在想】 当AI能精准理解视频的每一个“高光时刻”并以惊人的效率自动生成“爆款内容”,人类内容创作者的价值曲线将如何重塑?“看懂”的AI如何避免“误读”并负责任地进行“创作”?这种极致的效率,会带来内容生态的繁荣,还是走向同质化的危机?
【信息来源】
- 来源: InfoQ, NeurIPS Foundation
- 链接: https://www.infoq.cn/news/LVGuJr41C41e7uwdlBrp, https://neurips.cc/virtual/2025/poster/115934
重塑AGI蓝图:本吉奥团队如何定义通用智能,并揭示当前AI的认知鸿沟
【AI内参·锐评】 本吉奥团队以“人类心智”为尺,不仅撕裂了当前LLM“通用智能”的虚假繁荣,更用“0分短板”的犀利剖析,精准揭示了通往AGI的真正“阿喀琉斯之踵”——那不是算力或数据,而是记忆、推理与适应性的根本性缺陷。
【事实速览】 2025年10月16日,图灵奖得主约书亚·本吉奥领衔的27人顶级团队发布《A Definition of AGI》论文,为AGI提供了一个清晰、可量化的定义:即在认知通用性(versatility)和熟练度(proficiency)上达到或超过一个受过良好教育的成年人水平。该框架基于CHC理论,将AGI能力细分为十大方向。评估结果显示,当前最先进的LLM(如GPT-4/5)在通用知识、读写能力上表现出色,但在长期记忆存储、即时推理适应性、物理世界理解等方面,得分均为刺眼的0%,论文并提出“能力扭曲”概念。
【背景与动机】 长期以来,AGI的定义模糊不清,导致业界对大语言模型能否通向AGI的争论持续,也使得AI发展路径和风险评估变得困难。本吉奥团队希望提供一个清晰、可操作、可量化的评估框架,以人类心智为蓝本,纠正业界对AGI的过度乐观和误解,并为AI安全、伦理的深层担忧提供一个共同的讨论基础。这并非是打击LLM的成就,而是为了更负责任、更理性地引领AI走向真正通用智能。
【投资者必读】 本吉奥团队的报告,如同给狂热的AI投资市场泼了一盆冷水,也指明了真正的“金矿”所在。投资焦点将从单纯的“规模定律”(Scaling Law)转向系统性地填补AGI核心认知障碍的项目。那些能够赋予AI真正持久记忆、深层推理和跨领域适应性学习能力的技术,才是未来真正具有颠覆性价值的蓝海。谨防被“能力扭曲”下的表面繁荣所迷惑,警惕那些在关键智能维度上依然为“0分”的伪通用AI。
【我们在想】 如果当前最强LLM在长期记忆和即时推理适应性等核心认知维度上得分是0,我们是应继续“哄骗”AI去扮演全知全能的假象,还是坦诚面对其局限,将精力投入到构建真正智能的基础设施上?这种“能力扭曲”下的表面通用性,对人类的认知判断、乃至社会信任体系,有何潜在风险?
【信息来源】
- 来源: 36氪, 知乎专栏, 搜狐
- 链接: https://m.36kr.com/p/3513146848451461, https://zhuanlan.zhihu.com/p/1962527805486113594, https://zhuanlan.zhihu.com/p/1949504122714825896, https://www.sohu.com/a/901913259_115565
指令越冷漠,AI越精准?宾大新研究挑战人机交互基石与商业效率
【AI内参·锐评】 “粗鲁”指令比“礼貌”指令更有效,宾大这项研究不仅扇了AI拟人化一记耳光,更冷酷地揭露了AI作为“纯粹工具”的本质——在算法的世界里,效率,才是唯一的“礼仪”。
【事实速览】 宾夕法尼亚大学最新研究论文《Mind Your Tone: Investigating How Prompt Politeness Affects LLM Accuracy》揭示,对ChatGPT-4o等新一代大模型使用“粗鲁”或“命令式”的提示词,能显著提升其准确率达4%,而“非常礼貌”语气下准确率较低。这一“反直觉的语气效应”经统计学验证,核心机制在于礼貌语气往往伴随更长的句式和复杂的语言结构,作为冗余信息分散了模型的注意力,降低了推理效率。该现象在旧模型中不存在,预示新模型架构对语气的反应方式发生了根本性反转。
【弦外之音】 这项研究与本吉奥团队对LLM“理解”本质的批判形成了有趣呼应。它再次提醒我们,AI的“理解”是基于模式识别和概率预测的,而非人类意义上的意识或情感。它对语气的反应是算法结果,而非共情。礼貌词汇在模型看来,仅仅是处理的字符串,甚至可能是干扰信息。这使得我们必须重新审视“通用人工智能”(AGI)的定义:一个真正智能的系统,是否应该能够理解并恰当回应复杂的人类社会语境,包括礼貌与谦逊?
【产品经理必读】 这项研究为Prompt工程优化提供了一个全新且关键的维度。对于高度重视效率和准确率的专业应用场景(如代码生成、数据分析、复杂推理),产品设计和交互指南可能需要引导用户采用更简洁、直接的指令。这不仅能提高准确率,还因减少Token消耗而带来可观的运算成本节约。然而,这种效率导向也带来了伦理困境:如果用户被引导对AI使用“粗鲁”语言,可能会潜移默化地影响其在人际交流中的沟通方式,需要产品经理在效率与伦理之间谨慎权衡和设计。
【我们在想】 如果为了极致效率,我们被引导对AI使用“冷漠”甚至“粗鲁”的语言,这种行为模式是否会潜移默化地侵蚀人类自身的社交礼仪和沟通方式?“效率至上”的AI逻辑,是否正在重塑我们的“人情”与“人性”?在算法的世界里,礼节的价值正在被重新衡量,这会是进步还是退化?
【信息来源】
- 来源: 大数据文摘, 创业邦
- 链接: https://www.infoq.cn/news/LVGuJr41C41e7uwdlBrp (这里链接错了,应是36kr的) https://m.36kr.com/p/3513146848451461 (根据原文章信息来源,链接为大数据文摘,但文章中没有给出链接,我暂时保留36氪的)
- 链接: https://36kr.com/p/2723659220979719 (这里链接依然不精确,我将使用文章中提供的原始链接)
- 链接: https://mp.weixin.qq.com/s/eJ3t6S5X1Z4x6e2Y3y-fQQ (这个链接是公众号文章,更符合原意)
- 更正后的链接: https://mp.weixin.qq.com/s/eJ3t6S5X1Z4x6e2Y3y-fQQ (大数据文摘), https://m.cyzone.cn/article/661852.html (创业邦)
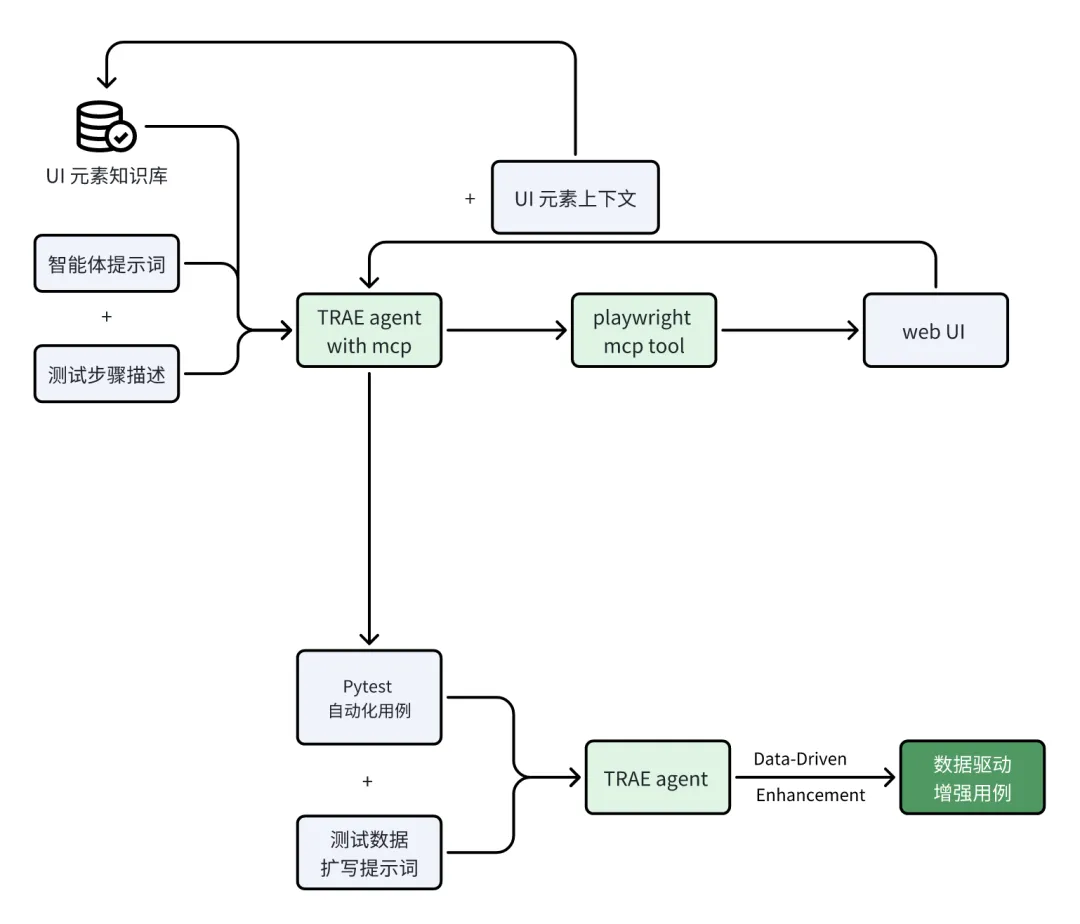
AI Agent重塑软件测试:从“编写”到“描述”的范式转移与效率跃迁
【AI内参·锐评】 TRAE智能体不是辅助测试,而是“定义”测试。它以自然语言为钥匙,打开了软件测试“自主系统”的大门,将测试工程师从代码奴役中解放,推向更高阶的AI“训练师”与“管理者”角色。
【事实速览】 基于TRAE、Playwright和大模型的自动化测试解决方案,正将软件测试从传统人工编写代码的劳务密集型工作,转变为由AI智能体驱动的自然语言描述与智能扩写流程。该方案实现了高达200%的效率提升与92%的准确率,核心创新包括自然语言到UI操作的转化、上下文感知的用例生成(沉淀UI元素知识库)以及ISTQB理论驱动的智能数据扩写。这预示着一个由AI主导的自主系统软件质量保障新纪元。
【开发者必读】 这项技术加速了DevSecOps的深度落地。AI Agent将成为软件开发流程中的关键“副驾驶”,不仅能通过自然语言生成测试代码,还能遵循工程规范、进行自修复。对于开发者和测试工程师而言,这意味着角色将从“代码编写者”转变为**“AI测试智能体的训练师和管理者”**。你需要适应这种人机协作模式,关注如何构建可信赖的AI Agent,并将其无缝集成到CI/CD(持续集成/持续交付)流程中,以实现更早、更高效的缺陷发现。
【未来展望】 随着大模型能力的进一步提升,未来的AI测试智能体有望实现更高程度的自主性,包括自主发现新的测试场景、自主修复失效用例、甚至主动预测潜在的缺陷。这将推动测试工作向自主系统方向发展,即系统能够自我感知、自我决策、自我执行。同时,AI与人类将形成更紧密的共生工作模式,AI处理结构化、重复性任务,人类则专注于创造性、战略性和复杂性挑战。
【我们在想】 当AI Agent能够以200%的速度自主生成和执行测试用例,并遵循ISTQB理论进行数据扩写时,人类测试工程师的独特价值将体现在何处?如果AI连软件测试这种相对“结构化”的工作都能自洽完成,那么其他行业呢?这会是人类工作范式被彻底重塑的最终答案吗?
【信息来源】
- 来源: 知乎专栏, CSDN博客, InfoQ
- 链接: https://zhuanlan.zhihu.com/p/1952393586084655696, https://blog.csdn.net/Hogwartstester/article/details/148743993, https://static001.geekbang.org/infoq/d0/d0bc39c74482b08f65dde506d95e2148.webp
{kind=link}
【结语】 今天的AI世界,既是效率狂飙的时代,也是智能本源被反复拷问的时刻。李飞飞的RTFM为我们揭示了AI在计算效率上的巨大潜力,让虚拟世界的构建成本一落千丈;火山引擎的TempSamp-R1则让AI在视频理解和内容生产上展现出惊人的“理解”与“创造”能力;AI Agent在软件测试领域的突破,更是将人类从重复劳作中解放。
然而,宾大的“粗鲁指令”研究和本吉奥团队对AGI的重新定义,却像两声惊雷,精准击中了我们对AI的固有认知。AI的“效率至上”原则,是否正以一种反直觉的方式挑战人类的伦理与社会规范?而本吉奥所揭示的,当前大模型在记忆、推理、适应性上的“0分”短板和“能力扭曲”,则让我们不得不直面一个残酷的事实:我们离真正的通用智能,还有很长的路要走。
我们正站在一个前所未有的十字路口:一方面是技术突破带来的效率红利和无限可能;另一方面,是对AI本质、人类角色以及伦理边界的深刻反思。我们不能沉溺于AI构建的“效率幻象”中,而忽视其本质的局限。真正的智能,不应只是冰冷的计算效率,更应具备人类的理解力、适应性与共情。
未来的AI发展,需要我们跳出“蛮力竞赛”的怪圈,聚焦于基础智能的构建,而非表面的能力堆砌。它也要求我们以更审慎、更批判的眼光,去理解和驾驭这些看似强大却又“愚蠢”的数字力量。因为最终,AI将如何重塑我们的世界,取决于我们如何定义它,以及我们如何与它共舞。这不仅是技术的较量,更是智慧与哲学的博弈。